
锁与Reflex空想
4.1 程序分析题:锁
- 基于标志(flag)的锁实现方式:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void init(lock_t *mutex) {
// 0 -> lock is available, 1 -> held
mutex->flag = 0;
}
void lock(lock_t *mutex) {
while (mutex->flag == 1) // TEST the flag
; // spin-wait (do nothing)
mutex->flag = 1; // now SET it!
}
void unlock(lock_t *mutex) {
mutex->flag = 0;
}
4.1.1
第10行的注释,spin-wait,是什么意思?
自旋等待,当执行lock时,就会什么都不干,不断的检测flag
4.1.2
假设没有底层硬件或操作系统的相关支持,该锁用于进程间的互斥则其实现方式 会有什么问题?请详细说明。
没有底层硬件和操作系统的支持,无法保证操作原子性,就是执行完A进程的某一行代码,就有去执行B进程的,没有完整的执行完一个进程的代码,例如上面的代码,可能会导致两个进程同时被锁。
原本应该一体的flag设置和检测的原子性无法得到保证,可能会被分开执行。
Test-and-Set原子指令的实现逻辑
2
3
4
5
int old = *old_ptr; //fetch old value at old_ptr
*old_ptr = new; //store ‘new’ into old_ptr
return old; //return the old value
}基于Test-and-Set指令的锁实现方式:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int flag;
} lock_t;
void init(lock_t *lock) {
// 0: lock is available, 1: lock is held
lock->flag = 0;
}
void lock(lock_t *lock) {
while (TestAndSet(&lock->flag, 1) == 1)
; // spin-wait (do nothing)
}
void unlock(lock_t *lock) {
lock->flag = 0;
}
4.1.3
“基于 Test-and-Set”指令的锁实现方式,是否可以解决 4.1.2 中,“基于标志 (flag)的锁实现方式”所存在的问题,为什么?
一个Test-and-Set(TAS)指令包括两个子步骤,把给定的内存地址设置为1,然后返回之前的旧值。
这两个子步骤在硬件上实现为一个原子操作,执行期间不会被其他处理器打断。
当第一个线程执行这段代码时,TAS指令会立即把lock设置为1,并返回0 ,线程退出while循环进入临界区。
如果另一个线程尝试进入临界区,TAS会把lock设置为1,但是也会返回1(由第一个线程的TAS指令设置为1),
此时第二个线程会一直while循环(忙等待),直到第一个线程退出临界区代码,执行了lock=0,即释放了锁。
所以TAS操作要么同时完成检测和设置操作,要么就都不做,可以解决上一个方式存在的问题。
4.1.4
假设系统中有 2 个线程 X 和 Y(优先级相同),它们之间通过“CPU 时间片轮转 调度策略”来分享底层唯一的一个 CPU 资源。其中,X 在某个时刻通过图 3 的 lock()获取 到了锁,并且需要运行 10 个时间片才会调用 unlock()来释放锁。请问,在此时间段内,Y 会分到时间片吗? 如果可以分到,那么 Y 是个什么运行形态? 此运行形态会带来什么样的负面效果?
因为调度规则已经指定为时间片轮转调度,而且CPU资源只有一个,所以当X在某个时刻通过lock获得了锁,在X的时间片结束以后,X就会被CPU移到就绪队列的队尾,此时Y便会开始执行,但是X还占据着锁,所以即使Y分到了时间片,也只会因为没有获取到锁而一直循环等待,占用着CPU,直到时间片用完,然后又轮到X,不断循环这个过程,等X运行完10个时间片,就能运行Y了。这会造成CPU利用率低的问题,而且执行等待的空指令也会带来额外的开销,造成资源浪费。
基于Linux的“Futex”锁实现方式:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
int v;
/* Bit 31 was clear, we got the mutex (the fastpath) */
if (atomic_bit_test_set(mutex, 31) == 0)
return;
atomic_increment(mutex);
while (1) {
if (atomic_bit_test_set(mutex, 31) == 0) {
atomic_decrement(mutex);
return;
}
/* We have to waitFirst make sure the futex value
we are monitoring is truly negative (locked). */
v = *mutex;
if (v >= 0)
continue;
futex_wait(mutex, v);
}
}
void mutex_unlock(int *mutex) {
/* Adding 0x80000000 to counter results in 0 if and
only if there are not other interested threads */
if (atomic_add_zero(mutex, 0x80000000))
return;
/* There are other threads waiting for this mutex,
wake one of them up. */
futex_wake(mutex);
}
4.1.5
该图中的第 4~5 行,和图中的第 8~11 行,具体实现什么作用? 它们是否有功 能冗余和冲突? 可以去掉当中的一个吗? 为什么?
- 4~5行,一个尝试获取锁的过程,自旋一次,若能获取,则该线程直接返回
- 8~11行,在被
futex_wait沉睡的线程经过unlock后被futex_wake唤醒,再通过TAS操作获得锁 - 不能去掉其中的一个,在这两段代码中有一句
atomic_increment(mutex);,这句话的作用是一个线程在执行futex_lock时,如果一开始没有在4~4行获得锁,则需要等待,并加入到等待队列,8~11行的代码的作用是让被唤醒的线程获取到锁退出,两者是互相配合的。
4.1.6
在第 24~25 行中的 if 语句是用来干什么的? 如果条件语句
atomic_add_zero (mutex, 0x80000000)为真,为什么要直接 return,为什么不直接执行第 29 行程序呢?
假如没有这个
if (v >= 0)语句,若线程A没有获取到锁,当它还没执行到futex_wait时,线程Cunlock了,此时等待队列为空,则mutex到最高位为0,futex_wake不会被调用,此时线程B会进入futex_wait,会导致线程B无法被唤醒。有了这个if语句以后,当最高位变为0以后,muetx也会变为0,线程B会进入if语句后执行
continue,在接下来的循环里,B会获得C释放的锁,就不会阻塞。若
atomic_add_zero(mutex, 0x80000000)为真,则说明等待队列长度为0,此时就没有线程需要futex_wake了,直接return可以减少系统调用的开销。
4.1.7
图 4 所展示的 Futex 锁实现方式,是否改进了 4.1.4 问题中提到的负面效果,为什么?
可以改进上面提到的负面效果,利用futex_wait可以让没有锁的线程睡眠,让有锁的线程占用CPU,更快完成任务,避免CPU不必要的浪费,避免不必要的线程进入CPU调度,可以提高性能。
4.2 运用系统思维对热门计算机技术进行分析和介绍
4.2.1 OK,现在轮到各位同学运用系统思维对英伟达公司的另外一个亮点 游戏技术 Nvidia Reflex 进行分析和介绍。
快乐游戏最重要的自然是画质和流畅度啦,不过要想打出好的操作,抛开个人技术不谈,低延迟才是王道。在玩网络游戏时,如果网络不好,就会造成高延迟,比如上一秒敌人还在这个位置,你丢了一个技能过去,下一秒你发现敌人其实早就去了另一个位置。又比如你突然发现无论怎么操作,角色都定住不动了,都是高延迟的表现,这种人我们一般称之为高ping战士。
单机游戏自然不存在网络延迟,但是设备所带来的系统延迟是无法避免的 。从点击键盘或鼠标到屏幕上渲染出来,要经过好几个步骤。
英伟达推出的这个 Nvidia Reflex 技术主要解决的是图里PC这个部分的问题。 Nvidia Reflex主要包括两个部分:
- 低延迟技术:
- NVIDIA Reflex SDK – 开发者 SDK,用于启用 NVIDIA Reflex 低延迟模式,从而在 GPU 密集型场景中降低延迟
- 延迟优化的驱动控制面板设置 – 增强的“首选最高性能”模式和“超低延迟”模式
- GeForce Experience 性能优化 – 一键式 GPU 超频自动优化工具
- 延迟测量工具:
- NVIDIA Reflex SDK 指标 – 游戏和渲染延迟标记使开发者能够在游戏中显示延迟指标
- NVIDIA Reflex 延迟分析器 – 360Hz G-SYNC 显示器的新功能率先实现了完整的端到端的系统延迟测量
- GeForce Experience 性能监控 – 提供侧栏和游戏中叠加显示,可显示包括延迟在内的实时性能指标
而重点分析的肯定是NVIDIA Reflex SDK,其他的只不过是一些设置,关键部分还是这个SDK。
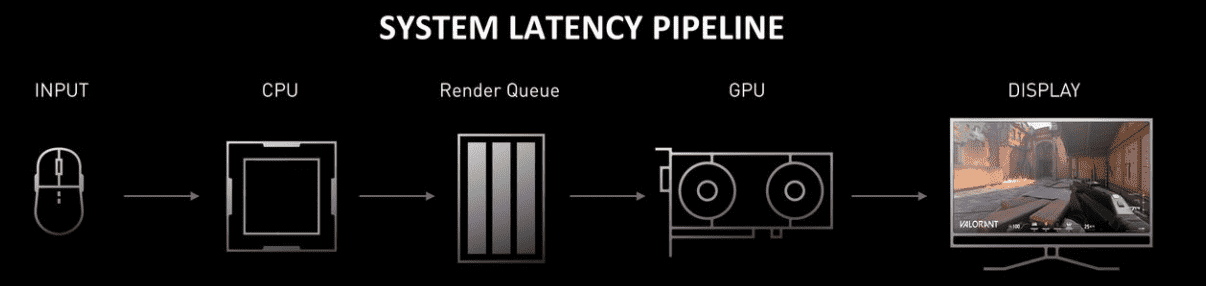
从这张图可以看出,从点击外设开始,先经过CPU再经过渲染队列,再通过GPU渲染才会呈现在屏幕上,SDK就是通过调控CPU和GPU的平衡来更快的处理渲染队列降低系统延迟,从而消除 GPU 渲染排队现象。
竞技游戏瞬息万变,因此会在受限于GPU和受限于CPU之间来回转换。根据这篇文章写的,应该是分为了两种情况:
- 游戏受 GPU 限制,这时候就会避免GPU作业大量排队。CPU 处理帧的速度快于 GPU 渲染帧的速度,造成了这种作业积压,从而导致渲染延迟增加。
- 游戏受 CPU 限制。Reflex SDK 将通过保持较高的 GPU 时钟频率来确保较低的延迟。
本质上来说,其实就是开发者在游戏中使用了SDK,这可以更好的控制CPU的运行速度,使其无法提前运行,这样就不会提交更多的任务给GPU,但是又要及时的提交作业,让GPU没有空闲时间,让CPU作业时间稍微延后,就能降低延迟,这就叫减少CPU反压。而在流程的内部,出现帧与帧之间排队也是司空见惯的。例如游戏引擎与渲染器上的最终GPU工作之间,实际上有数个待处理的帧正在排队,从而造成了延迟,这时候可能是GPU处理帧的速度赶不上CPU提交渲染请求的速度,这样就造成了CPU的反压。因此适当的丢掉一些无效的渲染请求就可以优化延迟。同样,在受GPU限制下,CPU也必须等待上一帧处理完成后,才能产生下一帧。
从网上看到一张有趣的图

其实NVIDIA Reflex技术就是用来缓解CPU与GPU之间的尴尬处境,消除GPU渲染队列。消除CPU渲染的“无用帧”,消除后压,并可立刻传送至显卡进行渲染。
在以前,如果没有Reflex,要想获得更低的输入延迟,你需要通过游戏自带的帧率限制器,因为通过限制帧率,我们机器上的GPU瓶颈被释放了,GPU渲染的速度更快,所以压力就不会到CPU这里。在这里Reflex可以保证帧率,同时也可以有效地减少你的输入延迟,因为它会动态地自我调整。原理是一样的,通过软件驱动层面,协调CPU和GPU的关系是非常重要的,就像CPU和内存的关系一样。
Reflex技术可以更好的从游戏中控制CPU的运行速度(估计是直接通过操作系统来操作我们CPU的工作流程),使CPU不能超前运行。并允许CPU及时向GPU提交作业,然后让GPU在作业管道中没有任何空闲的间隙来处理作业。而且,通过稍微推迟CPU作业的开始时间,为尽可能地对最后一毫秒的输入进行采样创造了机会,从而进一步减少了延迟。





